

Meriin Labs · original research · 14 June 2026 · every number below is computed by published code. See Reproduce this.
The claim: When an AI answer cites a page, it does not pull the page’s longest, most stat-laden sentence. It pulls a short, early, plain one. What would prove it wrong: drawn-from sentences matching the page baseline on length and position, with an equal or higher rate of containing numbers.
Our cross-engine study showed which sources AI engines cite. This one asks what they actually pull out of those sources. We fetched the cited pages, and for each citation found the source sentence whose content the engine’s answer most closely reflects, then compared those sentences to the rest of the page. The pattern is consistent and a little contrarian: AI answers draw from the short, early, plain sentences, not the long stat-dense ones.
Across 377 drawn-from sentences (a 94.5% match rate over 399 fetched citation-source pairs), the median drawn-from sentence ran 11 words against a page-wide median of 18, sat 27.8% of the way down the page, and contained a number only 17.5% of the time versus 29.2% for the average sentence on the same pages.
Hypothesis
Pre-registered before analysis. We expected drawn-from sentences to be shorter and earlier than the page baseline (extractability favours concision and lead position). We had no prior on numbers and, if anything, expected stat-bearing sentences to be over-represented, since GEO advice pushes “front-load the data.” Falsifier: drawn-from sentences indistinguishable from baseline on length and position.
Dataset
- Source pages: the cited URLs from the cross-engine study. Of 453 unique URLs, 316 fetched usable text (70%); the rest were bot-blocked, paywalled, JS-only, or thin.
- Drawn-from sentence: for each citation, the source sentence whose content words most overlap the engine’s answer, above a fixed threshold. 377 matched across 399 pairs with a page.
- Baseline: every sentence on each source page (length, position, whether it contains a number).
- Collected: 2026-06-14. Provenance: Public / self-collected data only. No client data.
Method
- Fetch each cited URL and extract visible text.
- Split each page into sentences; record each sentence’s word count, position on the page, and whether it contains a number (the page baseline).
- For each citation, take the engine’s answer, and score every source sentence by the share of its content words that appear in the answer. The top scorer above threshold is the drawn-from sentence.
- Compare drawn-from sentences to the page baseline on length, position, and number rate.
This is lexical matching, deliberately offline and reproducible, not embeddings. It is coarse: it sometimes lands on a heading or a boilerplate line (a “consult a healthcare provider” disclaimer was a real match). Treat the magnitudes as directional.
Results
| Axis | Drawn-from sentences | Page baseline | Read |
|---|---|---|---|
| Median length | 11 words | 18 words | ~40% shorter |
| Position on page | top 27.8% | uniform (50%) | front-loaded |
| Contains a number | 17.5% | 29.2% | 0.6x, under-represented |
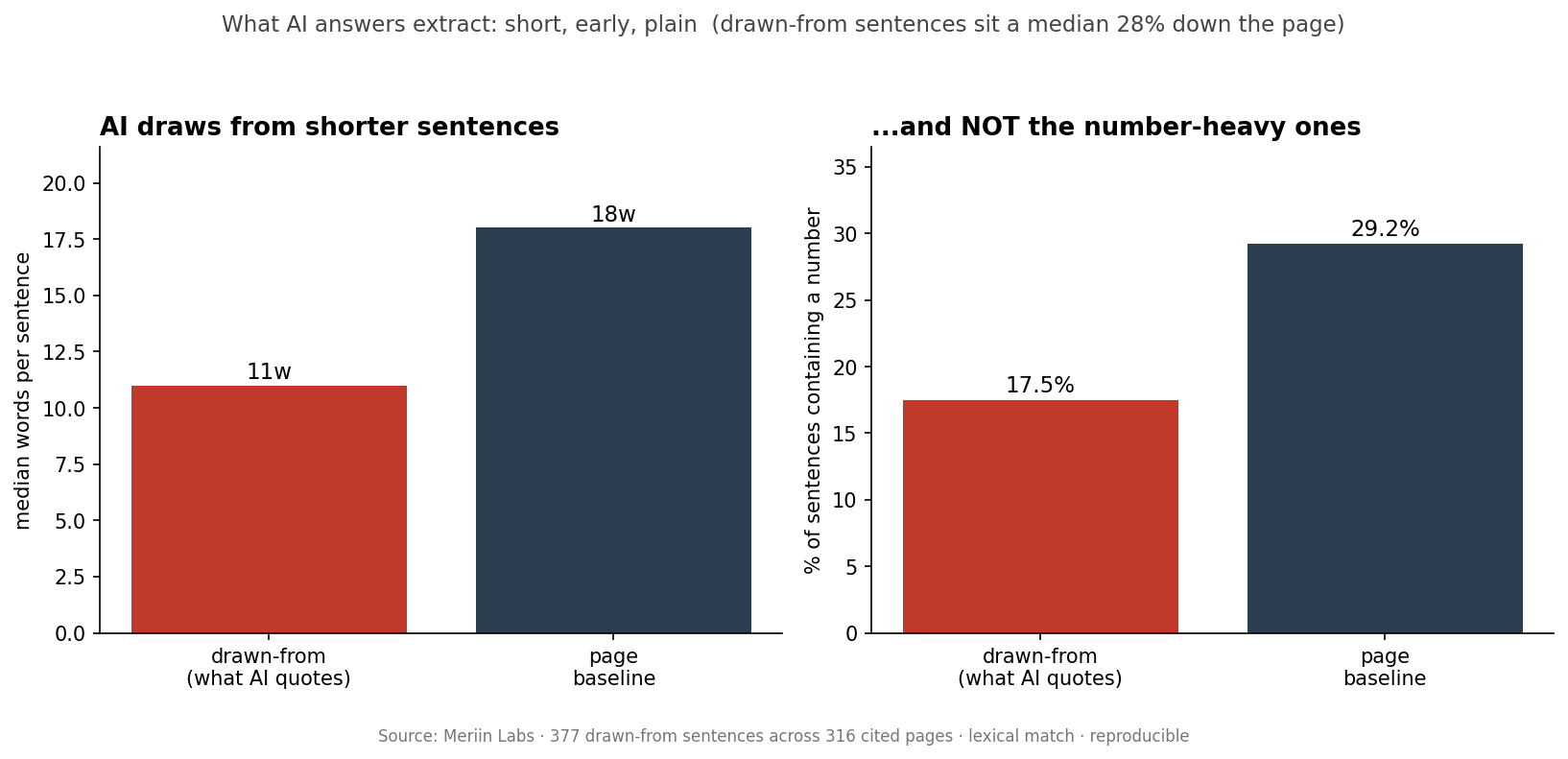
Finding 1: short wins. The sentence an AI answer reflects is, at the median, 11 words against the page’s 18. Extractable means quotable in one breath.
Finding 2: early wins. Drawn-from sentences cluster in the top third of the page (median 27.8% down), not spread evenly. Lead position is not just an SEO nicety; it is where extraction happens.
Finding 3: the numbers surprise. We expected stat-laden sentences to be favoured. The opposite held: a sentence with a number was less likely to be the drawn-from one (17.5% vs 29.2%, a 0.6x ratio). AI answers lift the concise explanatory line and paraphrase the statistics around it, rather than quoting the dense numeric sentence verbatim.
Confidence
- Counts (Tier-A). 377 matched sentences over 399 fetched pairs, computed by script.
- Direction (Tier-B). Shorter, earlier, less-numeric are consistent and survive the obvious noise. The numbers result in particular is robust in sign even if the magnitude moves.
- Magnitudes (Tier-C). Lexical overlap is a blunt instrument. It catches some headings and boilerplate, and “position on page” runs over extracted-text order (which includes nav), so exact figures will shift under a cleaner method.
Limitations
- Lexical, not semantic. Content-word overlap, not embeddings, picks the drawn-from sentence. An embeddings pass (the planned v2) will sharpen which sentence truly matches and drop boilerplate.
- Fetch bias. 70% of pages fetched; bot-blocked and JS-heavy pages are missing and may differ systematically.
- Position is noisy. Extracted-text order includes menus and footers, so “27.8% down the page” is a proxy for “early,” not a precise article coordinate.
- One snapshot, source-level citations. The engines cite sources, not spans, so the drawn-from sentence is inferred, not declared.
How this compares to prior work
GEO guidance says three things: lead with the answer, keep sentences short, and front-load your stats. This data backs the first two with evidence (short and early really are what get drawn out) and complicates the third: the sentences AI actually extracts are less numeric than average. The practical edit is to write a tight, plain, lead sentence that states the claim in ~11 words, and let the numbers support it in the following lines rather than cramming them into the sentence you most want quoted.
Reproduce this
In data/cited-sentences/:
fetch.py: fetches the cited pages and extracts text.analyze.py: finds the drawn-from sentence per citation and computes the comparison.cited_sentences.csv: every drawn-from sentence with its length, position, and number flag.FIGURES-LEDGER.csv: every number in this article.
Run python3 fetch.py then python3 analyze.py (reads the S4 corpus, so run that collection first).
The number
Across 377 source sentences that ChatGPT, Gemini and Perplexity drew from, the median ran 11 words against the page’s 18, sat in the top 28% of the page, and contained a number only 17.5% of the time versus 29.2% for the average sentence. AI extracts the short, early, plain line, not the dense stat.
Changelog & validity
- Valid as of 2026-06-14. Reflects the cross-engine corpus and the pages reachable on that date.
- v2 will replace lexical matching with embeddings and filter headings/boilerplate; the direction is expected to hold, the magnitudes to sharpen.
- v1.0, 14 June 2026: first publication under the Meriin Labs team byline. 316 pages fetched, 377 sentences matched, figures-ledger written.
Want the lead sentence of your key pages engineered for extraction? → Book a growth audit
Related: AI engines barely agree on sources · Can an LLM judge a sentence’s citability?
Back to the Lab

