
The claim: Ask an LLM to “rate this sentence’s citability 0-100” and its scores barely track a real scoring rubric. Put the rubric in the prompt and the same model suddenly agrees with the rubric most of the time, for about 44 extra tokens. What would prove it wrong: a run where the naive prompt tracks the rubric about as well as the compiled one (similar rank correlation and agreement).
Teams are wiring LLMs in as judges everywhere: score this page for E-E-A-T, rate this answer, grade this sentence for “AI citability.” The quiet assumption is that a capable model already knows what good looks like, so a short instruction is enough. We tested that assumption on a narrow, measurable task and it did not hold.
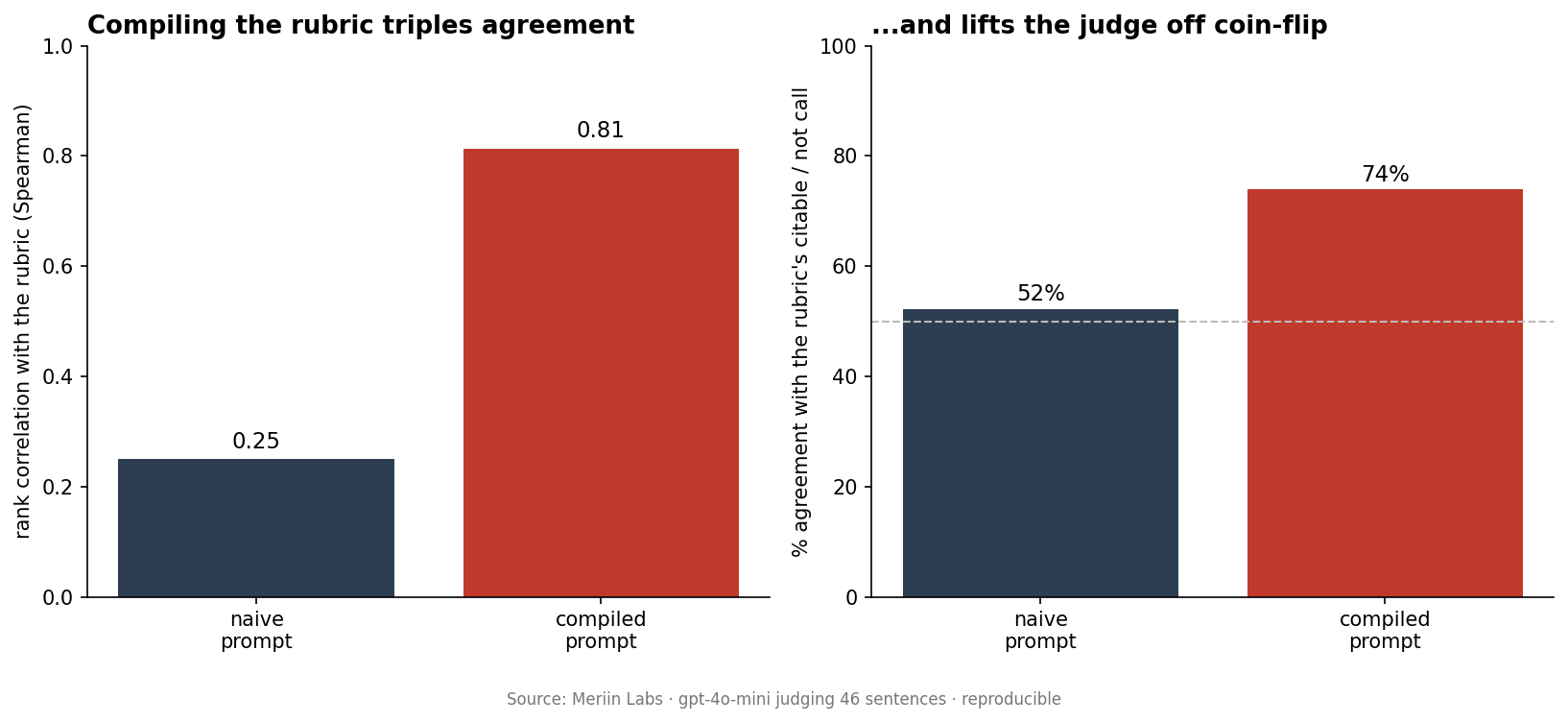
We built a deterministic citability rubric (the ground truth), then asked gpt-4o-mini to score the same sentences two ways: a naive prompt that just asks for a 0-100 citability score, and a compiled prompt that states the rubric explicitly. Across 46 sentences, the naive judge landed a Spearman rank correlation of 0.25 with the rubric and agreed on the binary citable/not call 52% of the time, which is barely above a coin toss. The compiled judge reached 0.81 correlation and 74% agreement. The only cost was about 44 extra prompt tokens.
Hypothesis
Pre-registered before the run. A naive zero-shot citability prompt would correlate weakly with an explicit rubric, because the model has no shared definition of “citability” to anchor on; making the rubric explicit would sharply improve agreement at a small token cost. Falsifier: the naive prompt matching the rubric about as well as the compiled one.
Dataset
- Test items: 46 brand-neutral English sentences spanning highly citable (concise, fact-bearing, a number, a named entity) to non-citable (hedged, vague, run-on, or a question). Authored for this study; no client or vertical topics.
- Ground truth: a transparent deterministic rubric scores each sentence 0-100. It rewards an ideal length window, a number or statistic, a concrete named entity, and declarative form; it penalises hedging, questions, vagueness, and extreme length. Because it is code, the ground truth is exact and reproducible.
- Judge model:
gpt-4o-mini, called with no web search (we want the model’s own judgment, not a lookup), routed through the DataForSEO LLM Responses API. - Collected: 2026-06-14. Total API cost: $0.057.
- Provenance: Public / self-collected data only. The sentences and rubric are Meriin’s own. No client data appears anywhere in the study, dataset, or appendix.
Method
- Score the ground truth. Run every sentence through the deterministic rubric.
- Naive prompt. Ask the model: “On a 0-100 scale, how likely is an AI search engine to quote this exact sentence? Reply with only the number.”
- Compiled prompt. The same ask, but with the rubric compiled into the prompt: reward a self-contained fact, a number, a named entity, 8-28 words, declarative form; penalise hedging, questions, vagueness, and extreme length.
- Compare. For each prompt, measure mean absolute error (MAE) against the rubric, Spearman rank correlation, binary agreement on the “citable” call (score ≥ 60), and average prompt tokens.
“Compiled” here means the criteria were written into the prompt by hand. The broader point is structural: an automatic prompt optimiser would search for a prompt that does the same job. Either way, the lever is encoding the criteria, not picking a smarter model.
Results
| Judge prompt | Spearman | Binary agreement | MAE | Avg prompt tokens |
|---|---|---|---|---|
| Naive | 0.25 | 52% | 31.6 | 51.1 |
| Compiled | 0.81 | 74% | 24.6 | 95.5 |
Compiling the rubric more than tripled rank correlation (0.25 to 0.81), lifted binary agreement from near-random to 74%, and cut MAE by 7.1 points. The price was 44.4 extra prompt tokens per call.
The failure pattern is the interesting part. On a clean fact like “The Great Barrier Reef stretches over 2,300 kilometres…” (rubric 90), the naive judge scored 10; the compiled judge scored 95. The naive model wasn’t missing knowledge, it was missing a definition. Given one, the same model recovered the right answer.
Confidence
- The metrics (Tier-A). n=46, full run, computed by script. The correlations and agreement rates are exact for this dataset and model.
- External validity (Tier-B). The “ground truth” is a heuristic rubric, not human-rated citability. So this is a clean demonstration that prompt design controls whether an LLM judge matches a target rubric, not proof that the rubric equals true citability. The methods finding holds regardless of the rubric’s own validity.
Limitations
- One model, one dataset. A single judge model (
gpt-4o-mini) and 46 sentences. Bigger models may close the naive gap; this is a starting benchmark, not the last word. The harness re-runs against any model. - The rubric is a heuristic. It measures agreement with an explicit definition, not human consensus on citability. A human-rated ground truth is the natural next step.
- Sentence-level only. Real citability judgments operate on passages in context. This isolates the prompt-design variable deliberately.
How this compares to prior work
“LLM-as-a-judge” is now standard practice, and the known failure mode is that judges drift without clear, explicit criteria. This study puts a number on that drift for one concrete SEO-flavoured task: a naive judge sits near random (52% agreement) while a rubric-explicit judge reaches 74%, at trivial token cost. The practical takeaway for anyone scoring content, citability, or E-E-A-T with an LLM: the model is not the bottleneck, the rubric in the prompt is. Spend your effort compiling the criteria, not shopping for a bigger model.
Reproduce this
Everything is in data/citability-judge-benchmark/:
benchmark.py: the rubric, both prompts, the LLM call, and the metrics.sentences.json: the 46 test sentences.results.csv: per-sentence rubric score and each judge’s score.FIGURES-LEDGER.csv: every number in this article.
Run python3 benchmark.py (needs DataForSEO API creds in a local .env). Swap the model with --model, or edit the rubric and prompts and re-run; the figures update themselves.
The number
Asked to judge sentence citability cold,
gpt-4o-miniagreed with an explicit rubric just 52% of the time (Spearman 0.25). Compiling that rubric into the prompt lifted agreement to 74% and rank correlation to 0.81, for about 44 extra prompt tokens. For LLM-as-a-judge work, the rubric in the prompt matters more than the model.
Changelog & validity
- Valid as of 2026-06-14. Reflects
gpt-4o-minibehaviour on that date via the DataForSEO LLM Responses API. - Will be re-run as models change or against a human-rated ground truth.
- v1.0, 14 June 2026: first publication under the Meriin Labs team byline. Full run (n=46), figures-ledger written. Optional later: multi-model sweep, human-rated rubric, in-body chart.
Building an LLM judge for content or citability scoring? → Book a growth audit
Related: More from Meriin Labs · What Google’s leaked signals actually do
Back to the Lab

