

Meriin Labs · original research · 14 June 2026 · every number below is computed by published code. See Reproduce this.
The claim: There is no single “AI search” to optimize for. ChatGPT, Gemini and Perplexity cite mostly different sources for the same question, in very different volumes. What would prove it wrong: a large majority of cited domains appearing across two or more engines, i.e. the engines converging on a shared source set.
Most GEO advice talks about “getting cited by AI” as if AI were one thing. We ran the same 25 informational questions through ChatGPT, Gemini and Perplexity with web search on, logged every source each one cited, and the single-AI assumption fell apart. The three engines produced 559 citations to 322 distinct domains, and only 28% of those domains were cited by more than one engine. Just 13 domains were cited by all three. Almost three quarters of the time, a “winning” AI citation is a win on exactly one engine.
Hypothesis
Pre-registered before collection. If “AI citations” were a universal target, the engines would converge: most cited domains would appear across multiple engines. We expected the opposite, that each engine runs its own retrieval and the overlap would be low. Falsifier: a majority of domains shared across engines.
Dataset
- Queries: 25 brand-neutral, global-English informational questions across health, finance, tech, how-to, product research, science, travel, cooking, legal, career, and environment. No client or vertical topics.
- Engines: ChatGPT (
gpt-4o-mini), Gemini (gemini-2.5-flash), Perplexity (sonar), each called through the DataForSEO LLM Responses API with web search enabled, returning the answer plus its source citations and fan-out queries. - Unit: the cited domain. 559 citations resolved to 322 domains. Gemini cites via grounding-redirect URLs; we resolved each to its real destination so domains are comparable.
- Collected: 2026-06-14. Total API cost: $1.76. Errors: 0 across 75 calls.
- Provenance: Public / self-collected data only. The prompts and code are Meriin’s own. No client data appears anywhere.
Method
- Collect. Run all 25 prompts through each engine; save every raw response immutably.
- Extract. Pull the answer text, the citation list (title + URL), and fan-out queries from each response. Resolve Gemini’s grounding redirects to real URLs.
- Classify. Reduce each citation to a domain; tag a source type with a transparent heuristic (encyclopedia, forum/UGC, video, medical, gov, edu, or commercial as the catch-all).
- Measure. Citations per answer per engine, distinct domains, cross-engine overlap, citation concentration (Herfindahl index), and source-type mix.
Results
Finding 1: the engines barely overlap. Of 322 domains, 232 (72%) were cited by exactly one engine, 77 by two, and only 13 by all three. Put the other way, only 28% of cited domains reached more than one engine. The shared set is small and predictable (YouTube, Wikipedia, Healthline, Mayo Clinic, IBM, Fidelity, Indeed, Chase). Everything else is engine-specific.
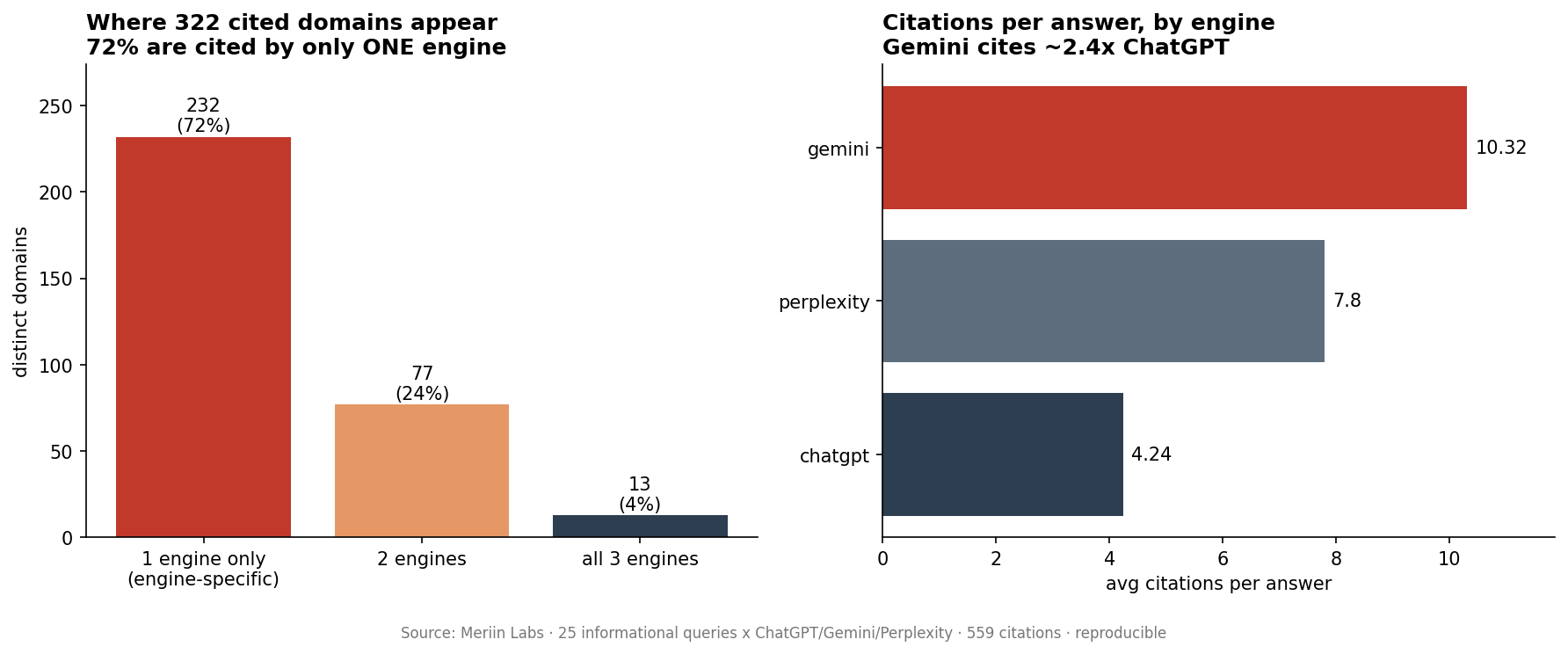
Finding 2: citation volume varies 2.4x by engine.
| Engine | Citations / answer | Unique domains | Fan-out queries (25 prompts) |
|---|---|---|---|
| ChatGPT | 4.24 | 61 | 25 |
| Perplexity | 7.80 | 150 | 0 |
| Gemini | 10.32 | 214 | 69 |
Gemini cites roughly 2.4 times as many sources per answer as ChatGPT, and is the only engine that meaningfully expands the query into a fan-out (69 sub-queries vs ChatGPT’s 25 echoes of the original). Your share of an answer’s citations depends heavily on which engine you are measuring.
Finding 3: generative citation is dispersed, not concentrated. The citation Herfindahl index is 0.0092 (near zero), the single most-cited domain (youtube.com) took 38 citations, and the top 10 domains together account for only 19.9% of all citations. Across these three engines, generative search spread 559 citations over 322 domains. That is the opposite of a winner-take-all surface.
Finding 4: commercial sources dominate; UGC and encyclopedias are marginal. Of 559 citations, 434 went to commercial domains, with video 38 (mostly YouTube), medical 31, edu 29, gov 17, and forum/UGC and encyclopedia barely registering at 6 and 4. The “AI loves Reddit and Wikipedia” story did not hold for ChatGPT, Gemini or Perplexity on these queries, though Gemini leaned on Wikipedia and Reddit far more than the other two did.
Confidence
- Overlap, volume, dispersion (Tier-A). These are a full census of the run, computed by script. The 28% overlap, the per-engine citation counts, and the concentration index are exact for this dataset.
- Source-type mix (Tier-B). “Commercial” is a catch-all for anything outside the named buckets, so the 78% commercial figure is partly a classifier artifact and should be read as “most cited sources are ordinary websites, not UGC or encyclopedias,” not as a precise taxonomy.
Limitations
- Pilot scale. 25 queries, English, informational intent. Enough to break the single-AI assumption, not enough to generalize per vertical. The harness scales to any query set.
- Three engines, not all of them. This covers ChatGPT, Gemini and Perplexity. It does not cover Google AI Overviews or AI Mode, where the Reddit/Wikipedia pattern is more often reported. The contrast is itself a finding: engine choice changes the answer.
- Source-level, not sentence-level. The data shows which sources were cited, not the exact sentence quoted. Locating the quoted passage on each source page is a defined next phase.
- One snapshot. Engine retrieval changes; these numbers are dated, and the appendix lets anyone re-run them.
How this compares to prior work
The dominant GEO narrative, much of it drawn from Google AI Overview studies, says AI search concentrates on a handful of UGC and encyclopedia domains. On ChatGPT, Gemini and Perplexity we found the reverse: dispersed citation (HHI 0.009), commercial-dominated, with only 28% cross-engine agreement. Both can be true at once, which is the real lesson: “AI search” is not one retrieval system, and advice that treats it as one will be right for one engine and wrong for the others. The actionable version is to pick the engine that matters for your audience and optimize for its retrieval, not for a mythical universal AI.
Reproduce this
Everything is in data/cross-engine-citations/:
collect.py: pulls each engine via the DataForSEO LLM Responses API.extract.py: parses citations, resolves Gemini redirects, computes the metrics.seed_prompts.json: the 25 queries.citations.csv,cross_engine.csv,engine_summary.csv: the full per-citation and per-domain data.FIGURES-LEDGER.csv: every number in this article.
Run python3 collect.py then python3 extract.py (needs DataForSEO API creds in a local .env).
The number
The same 25 questions, asked of ChatGPT, Gemini and Perplexity, produced 559 citations to 322 domains. Only 28% of those domains were cited by more than one engine, and just 13 by all three. Gemini cited 2.4 times as many sources per answer as ChatGPT. There is no single “AI search” to optimize for.
Changelog & validity
- Valid as of 2026-06-14. Reflects each engine’s retrieval behaviour on that date via the DataForSEO LLM Responses API.
- Will be re-run at larger scale and per vertical; a sentence-level phase (locating the quoted passage on each source) is the planned extension.
- v1.0, 14 June 2026: first publication under the Meriin Labs team byline. Full pilot (25 queries × 3 engines), figures-ledger written, no-client-data and figures traces clean.
Want to know which engine actually cites your category, and what it cites? → Book a growth audit
Related: More from Meriin Labs · Can an LLM judge a sentence’s citability?
Back to the Lab

